
Unlock your coding potential with the Frontend Developer Complete Digital Course 2024 – Free access to the latest tools, techniques, and trends in web development. Master HTML, CSS, JavaScript, and beyond, and build dynamic, responsive websites from scratch. Start your journey to becoming a pro developer today – no cost, just endless opportunity!
How The Internet Works 💻
Ever wonder what happens when you click a link? 🌐 How The Internet Works takes you behind the scenes of the digital world, breaking down complex tech into simple, bite-sized insights. From data packets to servers and beyond, discover the magic that powers your online experience!
What happens when you go to google.com?
The “g” key is pressed
Let me explain the physical keyboard actions and the OS interrupts. When you press the “g” key, the browser registers the event, triggering the auto-complete functions. Based on your browser’s algorithm and whether you’re in regular or private/incognito mode, various suggestions appear in a dropdown beneath the URL bar.
These suggestions are typically prioritized and sorted using factors such as your search history, bookmarks, cookies, and popular internet searches. As you continue typing “google.com,” numerous processes run in the background, and the suggestions refine with each keystroke. The browser might even predict “google.com” before you’ve finished typing.
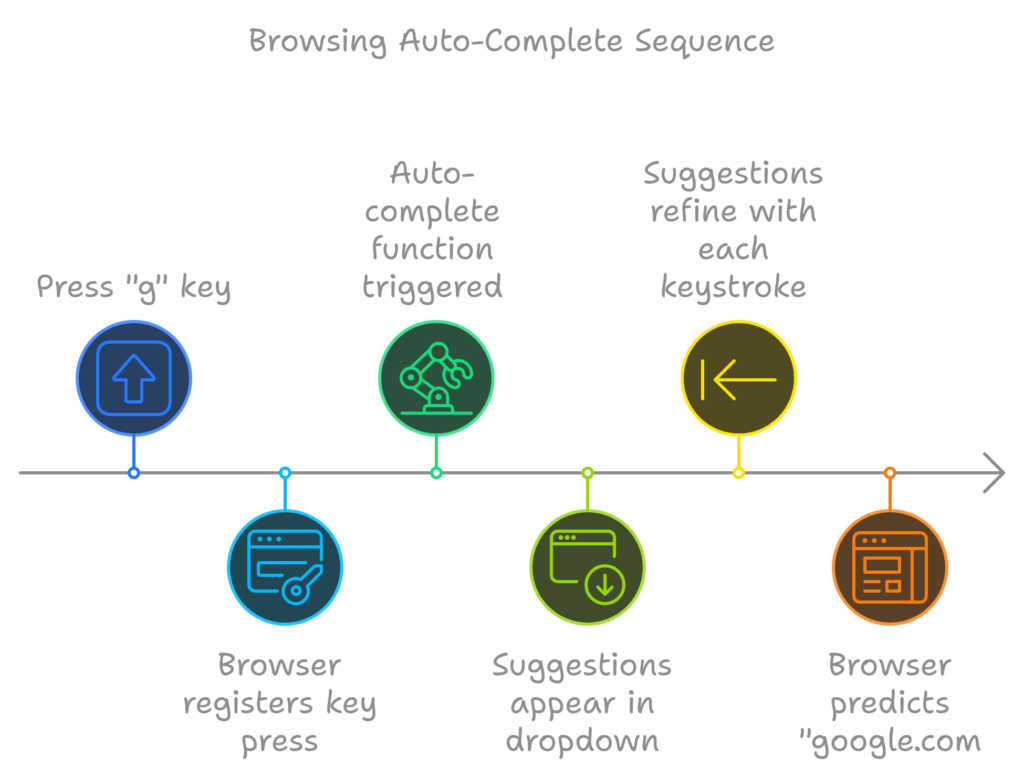
The “enter” key bottoms out
To establish a starting point, let’s consider the Enter key on a keyboard when it reaches the bottom of its travel range. At this moment, an electrical circuit dedicated to the Enter key is closed (either mechanically or capacitively), allowing a small current to flow into the keyboard’s logic circuitry. This circuitry scans the state of each key switch, filters out electrical noise from the rapid closure of the switch (debouncing), and translates the action into a keycode—in this case, the integer 13. The keyboard controller then encodes this keycode for transmission to the computer. Today, this is almost always done over a Universal Serial Bus (USB) or Bluetooth connection, though older systems used PS/2 or ADB.
In the case of a USB keyboard:
- The keyboard is powered by a 5V supply delivered through pin 1 of the computer’s USB host controller.
- The keycode generated by the keypress is stored in an internal register known as the “endpoint.”
- The USB host controller polls this “endpoint” roughly every 10ms (the minimum interval set by the keyboard), retrieving the stored keycode.
- The keycode is sent to the USB Serial Interface Engine (SIE), where it is converted into one or more USB packets in accordance with the USB protocol.
- These packets are transmitted over the D+ and D- lines (the two middle pins) at a maximum rate of 1.5 Mb/s, as the keyboard is classified as a “low-speed device” (per USB 2.0 standards).
- The computer’s host USB controller decodes this serial signal, and the Human Interface Device (HID) driver interprets the keypress. Finally, the key event is passed to the operating system’s hardware abstraction layer.

In the case of a virtual keyboard (such as on touch screen devices):
- When the user touches a capacitive touch screen, a small amount of current transfers to their finger. This interaction disturbs the electrostatic field of the screen’s conductive layer, creating a voltage drop at the point of contact.
- The screen controller detects this and triggers an interrupt, reporting the coordinates of the touch.
- The operating system then alerts the currently active application that a press event has occurred within its graphical interface, typically on a virtual keyboard button.
- The virtual keyboard application raises a software interrupt, which notifies the operating system of a “key pressed” event.
- The focused application receives this notification and processes the keypress accordingly.
Interrupt Fires [Not for USB Keyboards]
For non-USB keyboards, such as those using legacy connections (e.g., PS/2), the keyboard signals an interrupt via its interrupt request line (IRQ). This IRQ is mapped to an interrupt vector (an integer) by the system’s interrupt controller. The CPU consults the Interrupt Descriptor Table (IDT), which links each interrupt vector to a corresponding function known as an interrupt handler, supplied by the operating system’s kernel.
When the interrupt is triggered, the CPU uses the interrupt vector to index into the IDT and execute the appropriate interrupt handler. This process causes the CPU to transition into kernel mode, allowing the operating system to manage the keypress event.
A WM_KEYDOWN Message is Sent to the App (On Windows)
When the Enter key is pressed, the Human Interface Device (HID) transport passes the key down event to the KBDHID.sys driver, which converts the HID usage data into a scan code. In this case, the scan code is VK_RETURN (0x0D), representing the Enter key. The KBDHID.sys driver then communicates with the KBDCLASS.sys driver (the keyboard class driver), which securely manages all keyboard input. Before proceeding, the signal may pass through any third-party keyboard filters installed on the system, though this also happens in kernel mode.
Next, Win32K.sys comes into play, determining which window is currently active by invoking the GetForegroundWindow() API. This function retrieves the window handle (hWnd) of the active application, such as the browser’s address bar. At this point, the Windows “message pump” calls SendMessage(hWnd, WM_KEYDOWN, VK_RETURN, lParam). The lParam parameter contains a bitmask that provides additional information about the keypress, including:
- Repeat count (which is 0 in this case),
- Scan code (which might be OEM-specific but typically standard for VK_RETURN),
- Extended key flags (indicating whether modifier keys like Alt, Shift, or Ctrl were also pressed, which they weren’t).
The SendMessage API queues the message for the specific window handle. Later, the system’s main message processing function (known as WindowProc) assigned to the window (hWnd) retrieves and processes messages in the queue.
The active window in this case is an edit control, and its WindowProc function has a message handler that responds to WM_KEYDOWN events. The handler checks the third parameter (wParam) passed by SendMessage, recognizes that the value is VK_RETURN, and thus determines that the user has pressed the Enter key. This triggers the appropriate response for the application.
A KeyDown NSEvent is Sent to the App (On OS X)
When a key is pressed on OS X, the interrupt signal triggers an event in the I/O Kit keyboard driver (a kernel extension or “kext”). This driver translates the hardware signal into a key code. The key code is then passed to the WindowServer, which manages the graphical user interface.
The WindowServer dispatches the key press event to the appropriate applications (such as the active or listening ones) by sending it through their Mach port, where it is placed into an event queue. Applications with the proper privileges can access this event queue by calling the mach_ipc_dispatch function.
Most applications handle this process through the NSApplication main event loop, which is responsible for processing user input. When the event is a key press, it is represented as an NSEvent of type NSEventTypeKeyDown. The application then reads this event and responds accordingly, triggering any code related to keypress actions based on the key code received.
The Xorg Server Listens for Keycodes (On GNU/Linux)
When a key is pressed in a graphical environment using the X server, the X server employs the evdev (event device) driver to capture the keypress event. The keycode from the physical keyboard is then re-mapped into a scancode using X server-specific keymaps and rules.
Once the mapping is complete, the X server forwards the resulting scancode to the window manager (such as DWM, Metacity, i3, etc.). The window manager, in turn, sends the character or key event to the currently focused window. The graphical API of the focused window processes this event and displays the corresponding symbol in the appropriate field, using the correct font, based on the key pressed.
This flow ensures that the character is correctly rendered in the active application’s interface, completing the keypress interaction from hardware to graphical output.
Parse URL
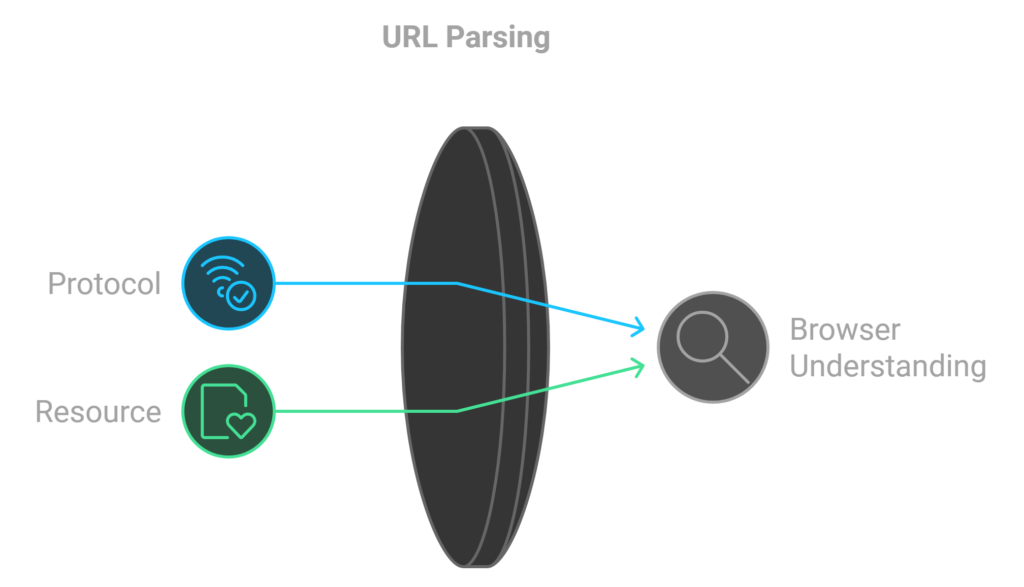
When the browser parses the URL(Uniform Resource Locator), it extracts the following components:
- Protocol:
"http"
The browser understands that this uses the Hyper Text Transfer Protocol to communicate with the server. - Resource:
"/"
This indicates that the browser should retrieve the main (index) page of the website, as the/path typically refers to the root or home page of the server.
Each of these components helps the browser interpret and fetch the desired resource from the web.
Is it a URL or a Search Term?
When no protocol (e.g., “http”) or valid domain name is provided, the browser interprets the text in the address bar as a potential search term. Instead of trying to resolve it as a URL, the browser forwards the text to its default web search engine.
In most cases, the browser appends a special identifier to the search query, indicating that the request originated from the browser’s URL bar. This allows the search engine to handle and prioritize these searches accordingly, improving the relevance of the results based on the context.
This process helps the browser determine whether it should attempt to navigate directly to a website or provide search results based on the entered text.
Convert Non-ASCII Unicode Characters in the Hostname
- The browser examines the hostname for any characters that fall outside the ASCII range, specifically those that are not in the sets of a-z, A-Z, 0-9, –, or ..
- In this case, the hostname is google.com, which contains only ASCII characters, so no conversion is necessary. However, if there were non-ASCII characters present in the hostname, the browser would apply Punycode encoding to convert the hostname into a valid ASCII representation. This process ensures that all characters in the hostname can be correctly processed by the network protocols.
Check HSTS List
The browser first checks its preloaded HSTS (HTTP Strict Transport Security) list, which contains websites that have explicitly requested to be accessed only via HTTPS.
If the requested website is found on this list, the browser automatically sends the request using HTTPS rather than HTTP. If the website is not in the HSTS list, the initial request is sent via HTTP.
It’s important to note that a website can still implement HSTS without being included in the preloaded list. In such cases, the first HTTP request made by the user will return a response instructing the browser to only send subsequent requests via HTTPS. However, this initial HTTP request could expose the user to a downgrade attack, where an attacker might intercept the request and force it to remain unencrypted. This vulnerability is why modern web browsers include the HSTS list, enhancing security for users by preventing insecure connections from being established in the first place.
DNS Lookup
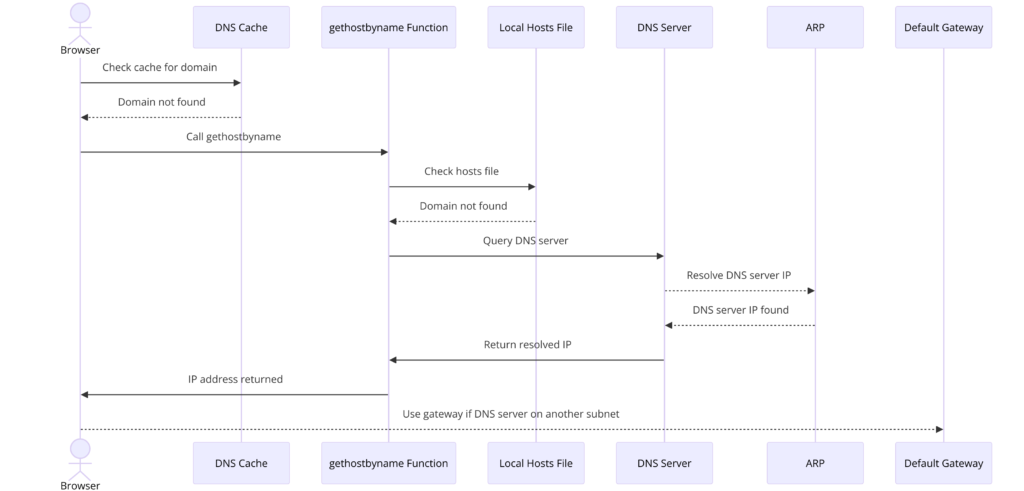
The browser begins the DNS lookup process by checking if the domain is already present in its cache. (To view the DNS cache in Chrome, navigate to chrome://net-internals/#dns.)
If the domain is not found in the cache, the browser calls the gethostbyname library function (the specific function may vary depending on the operating system) to perform the hostname resolution.
- Local Hosts File Check:
The gethostbyname function first checks if the hostname can be resolved by referencing the local hosts file, whose location varies by operating system. This file is a simple text file that maps hostnames to IP addresses and can provide a quick resolution without querying DNS. - DNS Server Request:
If the hostname is not cached and cannot be found in the hosts file, the browser then sends a request to the DNS server configured in the network stack. This server is typically the local router or the ISP’s caching DNS server, which stores previously resolved names to speed up future requests. - ARP Process for DNS Server:
- If the DNS server is on the same subnet, the network library follows the ARP (Address Resolution Protocol) process to resolve the IP address of the DNS server, ensuring that the request is directed correctly within the local network.
- If the DNS server is on a different subnet, the network library instead follows the ARP process for the default gateway IP, which acts as an intermediary to route the request to the appropriate subnet.
This systematic approach ensures that the browser efficiently resolves domain names to IP addresses, enabling it to establish a connection to the desired website. By checking the cache first, using the local hosts file, and finally querying the DNS server, the browser minimizes the time spent on hostname resolution.
| Operating System | Version(s) | Location |
|---|---|---|
| Unix, Unix-like, POSIX | /etc/hosts | |
| Microsoft Windows | 3.1 | %WinDir%\HOSTS |
| 95, 98, ME | %WinDir%\hosts | |
| NT, 2000, XP, 2003, Vista, 2008, 7, 2012, 8, 10, 11 | %SystemRoot%\System32\drivers\etc\hosts | |
| Windows Mobile, Windows Phone | Registry key under HKEY_LOCAL_MACHINE\Comm\Tcpip\Hosts | |
| Apple Macintosh | 9 and earlier | Preferences or System folder |
| Mac OS X 10.0–10.1.5 | (Added through NetInfo or niload) | |
| Mac OS X 10.2 and newer | /etc/hosts (a symbolic link to /private/etc/hosts) | |
| Novell NetWare | SYS:etc\hosts | |
| OS/2, eComStation, ArcaOS | “bootdrive”:\mptn\etc\ | |
| Symbian | Symbian OS 6.1–9.0 | C:\system\data\hosts |
| Symbian OS 9.1+ | C:\private\10000882\hosts | |
| MorphOS | NetStack | ENVARC:sys/net/hosts |
| AmigaOS | < 4 | AmiTCP:db/hosts |
| 4 | DEVS:Internet/hosts | |
| AROS | ENVARC:AROSTCP/db/hosts | |
| Android | /etc/hosts (a symbolic link to /system/etc/hosts) | |
| iOS | iOS 2.0 and newer | /etc/hosts (a symbolic link to /private/etc/hosts) |
| TOPS-20 | SYSTEM:HOSTS.TXT | |
| Plan 9 | /lib/ndb/hosts | |
| BeOS | /boot/beos/etc/hosts | |
| Haiku | /system/settings/network/hosts | |
| OpenVMS | UCX | UCX$HOST |
| TCPware | TCPIP$HOST | |
| RISC OS | 3.7, 5 | !Boot.Resources.!Internet.files.Hosts |
| later boot sequence | !Boot.Choices.Hardware.Disabled.Internet.Files.Hosts |
ARP Process
In order to send an ARP (Address Resolution Protocol) broadcast, the network stack library needs two key pieces of information: the target IP address that needs to be looked up and the MAC address of the interface that will be used to send out the ARP broadcast.
Checking the ARP Cache:
The ARP cache is first checked for an entry corresponding to the target IP address. If an entry exists, the library function returns the result in the format:
Target IP = MAC.
If the Entry is Not in the ARP Cache:
If there is no entry for the target IP address, the following steps are taken:
- The route table is consulted to determine whether the target IP address is on any of the subnets listed in the local route table.
- If it is found, the library uses the interface associated with that subnet.
- If not, the library defaults to using the interface that connects to the default gateway.
- The MAC address of the selected network interface is then retrieved.
Sending the ARP Request:
The network library constructs and sends a Layer 2 (data link layer of the OSI model) ARP request with the following format: ARP Request:
- Sender MAC: interface:mac:address:here
- Sender IP: interface.ip.goes.here
- Target MAC: FF:FF:FF:FF:FF:FF (Broadcast)
- Target IP: target.ip.goes.here Depending on the hardware setup between the computer and the router, the behavior of the ARP request varies:
- Directly Connected:
If the computer is directly connected to the router, the router will respond with an ARP Reply (see below). - Hub:
If the computer is connected to a hub, the hub will broadcast the ARP request out of all its other ports. If the router is connected to the same “wire,” it will respond with an ARP Reply (see below). - Switch:
If the computer is connected to a switch, the switch will check its local CAM/MAC table to identify which port has the MAC address being queried. If the switch has no entry for the MAC address, it will rebroadcast the ARP request to all other ports. If the switch does have an entry in its MAC/CAM table, it will send the ARP request only to the port that has the corresponding MAC address.- If the router is on the same “wire,” it will respond with an ARP Reply (see below).
ARP Reply:
The ARP reply will have the following format:
- Sender MAC: target:mac:address:here
- Sender IP: target.ip.goes.here
- Target MAC: interface:mac:address:here
- Target IP: interface.ip.goes.here
Now that the network library has obtained the IP address of either the DNS server or the default gateway, it can resume its DNS process:
- The DNS client establishes a socket connection to UDP port 53 on the DNS server, utilizing a source port above 1023.
- If the response size exceeds the UDP limit, TCP will be used instead to accommodate the larger response.
- If the local or ISP DNS server does not have the requested information, it will initiate a recursive search, querying a hierarchy of DNS servers until the SOA (Start of Authority) is reached, at which point the answer is returned.
Opening of a Socket
Once the browser receives the IP address of the destination server, it combines this with the port number specified in the URL (where HTTP defaults to port 80 and HTTPS to port 443). The browser then makes a call to the system library function named socket, requesting a TCP socket stream using AF_INET or AF_INET6 and SOCK_STREAM.
-
Transport Layer Processing:
- This request is first processed by the Transport Layer, where a TCP segment is crafted. The destination port is added to the header, and a source port is chosen from within the kernel’s dynamic port range (as specified by
ip_local_port_rangein Linux).
- This request is first processed by the Transport Layer, where a TCP segment is crafted. The destination port is added to the header, and a source port is chosen from within the kernel’s dynamic port range (as specified by
-
Network Layer Processing:
- This segment is then sent to the Network Layer, which wraps it in an additional IP header. The IP addresses of both the destination server and the current machine are inserted to form a packet.
-
Link Layer Processing:
- The packet next arrives at the Link Layer, where a frame header is added. This header includes the MAC address of the machine’s NIC (Network Interface Card) as well as the MAC address of the gateway (local router). If the kernel does not know the MAC address of the gateway, it must broadcast an ARP query to find it.
At this point, the packet is ready to be transmitted through one of the following methods:
- Ethernet
- WiFi
- Cellular Data Network
For most home or small business Internet connections, the packet will pass from your computer, possibly through a local network, and then through a modem (Modulator/Demodulator). This modem converts digital 1’s and 0’s into an analog signal suitable for transmission over telephone, cable, or wireless telephony connections. On the other end of the connection, another modem converts the analog signal back into digital data for processing by the next network node, where the from and to addresses would be analyzed further.
In contrast, larger businesses and some newer residential connections will use fiber or direct Ethernet connections, allowing the data to remain digital and be passed directly to the next network node for processing.
Eventually, the packet will reach the router managing the local subnet. From there, it will continue to travel to the autonomous system’s (AS) border routers, traverse other ASes, and finally arrive at the destination server. Each router along the way extracts the destination address from the IP header and routes it to the appropriate next hop. The time to live (TTL) field in the IP header is decremented by one for each router that processes it. The packet will be dropped if the TTL field reaches zero or if the current router has no space in its queue (which may occur due to network congestion).
This send and receive process happens multiple times following the TCP connection flow:
-
The client chooses an Initial Sequence Number (ISN) and sends a packet to the server with the SYN bit set to indicate it is setting the ISN.
-
The server receives the SYN and, if it is agreeable, performs the following:
- Chooses its own initial sequence number.
- Sets the SYN bit to indicate it is choosing its ISN.
- Copies the (client ISN + 1) to its ACK field and adds the ACK flag to indicate it is acknowledging receipt of the first packet.
-
The client acknowledges the connection by sending a packet that:
- Increases its own sequence number.
- Increases the receiver acknowledgment number.
- Sets the ACK field.
-
Data Transfer:
Data is transferred as follows:- As one side sends N data bytes, it increases its sequence number (SEQ) by that number.
- When the other side acknowledges receipt of that packet (or a string of packets), it sends an ACK packet with the acknowledgment (ACK) value equal to the last received sequence from the other side.
-
Closing the Connection:
To close the connection:- The side initiating the closure sends a FIN packet.
- The other side acknowledges the FIN packet and sends its own FIN.
- The initiating side acknowledges the other side’s FIN with an ACK.
TLS Handshake
- The client computer sends a
ClientHellomessage to the server, which includes its Transport Layer Security (TLS) version, a list of available cipher algorithms, and compression methods. - In response, the server replies with a
ServerHellomessage that specifies the TLS version, the selected cipher, the selected compression methods, and the server’s public certificate signed by a Certificate Authority (CA). This certificate contains a public key that will be used by the client to encrypt the remainder of the handshake until a symmetric key can be agreed upon. - The client verifies the server’s digital certificate against its list of trusted CAs. If trust can be established based on the CA, the client generates a string of pseudo-random bytes and encrypts this string using the server’s public key. These random bytes will be used to determine the symmetric key.
- The server decrypts the random bytes using its private key and utilizes these bytes to generate its own copy of the symmetric master key.
- The client sends a
Finishedmessage to the server, encrypting a hash of the transmission that has occurred up to this point with the symmetric key. - The server generates its own hash and then decrypts the hash sent by the client to verify that it matches. If the hashes match, the server sends its own
Finishedmessage back to the client, which is also encrypted with the symmetric key. - From this point forward, the TLS session transmits application (HTTP) data encrypted with the agreed-upon symmetric key.
This handshake process establishes a secure connection between the client and server, ensuring that data transmitted over the connection is protected from eavesdropping and tampering.
If a Packet is Dropped
Sometimes, due to network congestion or flaky hardware connections, TLS packets may be dropped before reaching their final destination. In such cases, the sender must decide how to react. The algorithm governing this response is known as TCP congestion control. The specific implementation can vary depending on the sender, with the most common algorithms being Cubic on newer operating systems and New Reno on many others.
- The client chooses a congestion window based on the maximum segment size (MSS) of the connection.
- For each packet acknowledged, the congestion window doubles in size until it reaches the ‘slow-start threshold.’ In some implementations, this threshold is adaptive and can change based on network conditions.
- Once the slow-start threshold is reached, the window increases additively for each packet acknowledged. If a packet is dropped, the window reduces exponentially until another packet is acknowledged.
This congestion control mechanism helps optimize network performance and stability, ensuring that data can be transmitted efficiently while minimizing the impact of packet loss.
HTTP Protocol
If the web browser used was developed by Google, instead of sending a standard HTTP request to retrieve a page, it may attempt to negotiate an “upgrade” from HTTP to the SPDY protocol with the server.
If the client is using the HTTP protocol and does not support SPDY, it sends a request to the server in the following format:
GET / HTTP/1.1
Host: google.com
Connection: close
[other headers]Here, [other headers] refers to a series of colon-separated key-value pairs formatted according to the HTTP specification and separated by single newlines. This assumes that the web browser is free of bugs that violate the HTTP specification and that it is using HTTP/1.1. If it were using a different version, such as HTTP/1.0 or HTTP/0.9, it might not include the Host header in the request.
HTTP/1.1 defines the “close” connection option for the sender to signal that the connection will be closed after the response is completed. For example:
Connection: closeHTTP/1.1 applications that do not support persistent connections MUST include the “close” connection option in every message.
After sending the request and headers, the web browser sends a single blank newline to the server to indicate that the content of the request is complete.
The server then responds with a response code that denotes the status of the request, structured as follows:
200 OK
[response headers]This is followed by a single newline and then the payload containing the HTML content of www.google.com. The server may either close the connection or, if requested by the headers sent by the client, keep the connection open for reuse in further requests.
If the HTTP headers sent by the web browser contained sufficient information for the web server to determine whether the version of the file cached by the web browser has been unmodified since the last retrieval (for example, if the web browser included an ETag header), the server may instead respond with:
304 Not Modified
[response headers]This response will have no payload, and the web browser will retrieve the HTML from its cache.
After parsing the HTML, the web browser (and server) repeats this process for every resource (image, CSS, favicon.ico, etc.) referenced in the HTML page. In these cases, instead of GET / HTTP/1.1, the request will be structured as:
GET /$(URL relative to www.google.com) HTTP/1.1If the HTML references a resource on a different domain than www.google.com, the web browser returns to the steps involved in resolving the other domain, following all steps up to this point for that domain. The Host header in the request will be set to the appropriate server name instead of google.com.
HTTP Server Request Handling
The HTTPD (HTTP Daemon) server is responsible for handling requests and responses on the server side. The most common HTTPD servers include Apache and Nginx for Linux, as well as IIS for Windows.
-
Receiving the Request: The HTTPD server receives the incoming request from the client.
-
Breaking Down the Request: The server analyzes the request and extracts the following parameters:
- HTTP Request Method: This could be one of several methods, including
GET,HEAD,POST,PUT,PATCH,DELETE,CONNECT,OPTIONS, orTRACE. In the case of a URL entered directly into the address bar, the method will typically beGET. - Domain: In this case, the domain is
google.com. - Requested Path/Page: Here, the requested path is
/, indicating that no specific page was requested; thus,/is treated as the default path.
- HTTP Request Method: This could be one of several methods, including
-
Verifying the Virtual Host: The server checks whether a Virtual Host is configured for
google.com. -
Method Verification: The server verifies that
google.comcan acceptGETrequests. -
Client Permission Check: The server checks if the client is allowed to use this method based on criteria such as IP address, authentication, etc.
-
Request Rewriting: If the server has a rewrite module installed (such as
mod_rewritefor Apache or URL Rewrite for IIS), it attempts to match the request against any configured rules. If a matching rule is found, the server rewrites the request according to that rule. -
Content Retrieval: The server retrieves the content that corresponds to the request. In this case, it will typically default to the index file since the request path is
/. While there are cases that can override this behavior, using the index file is the most common method. -
File Parsing and Processing: The server parses the index file according to the designated handler. If Google is using PHP, for example, the server will utilize PHP to interpret the index file and stream the output back to the client.
By following these steps, the HTTPD server efficiently processes incoming requests and returns the appropriate responses to the client.
Browser
The primary functionality of a browser is to present the web resources you choose by requesting them from a server and displaying them in the browser window. The resource is typically an HTML document but may also include PDFs, images, or other types of content. The location of the resource is specified by the user using a URI (Uniform Resource Identifier).
The way a browser interprets and displays HTML files is defined by the HTML and CSS specifications, which are maintained by the W3C (World Wide Web Consortium), the standards organization for the web.
Browser user interfaces share many common features, including:
- An address bar for entering a URI
- Back and forward buttons for navigation
- Bookmarking options for saving favorite pages
- Refresh and stop buttons for refreshing or halting the loading of current documents
- A home button that takes you to your home page
Browser High-Level Structure
The components of a browser can be broken down as follows:
- User Interface: This includes the address bar, back/forward buttons, bookmarking menu, and any other part of the browser’s display except for the window where the requested page is shown.
- Browser Engine: The browser engine acts as a bridge between the user interface and the rendering engine, managing actions and interactions.
- Rendering Engine: Responsible for displaying requested content, the rendering engine parses HTML and CSS, transforming the parsed content into a visual representation on the screen.
- Networking: This component handles network calls, such as HTTP requests, and utilizes different implementations tailored for various platforms while providing a platform-independent interface.
- UI Backend: The UI backend is responsible for drawing basic widgets like combo boxes and windows. It exposes a generic interface that is not specific to any platform and relies on the operating system’s user interface methods.
- JavaScript Engine: This engine parses and executes JavaScript code, allowing for dynamic content and interactivity within web pages.
- Data Storage: This acts as a persistence layer, enabling the browser to save various types of data locally, such as cookies. Browsers also support storage mechanisms like localStorage, IndexedDB, WebSQL, and FileSystem.
Each of these components works together to create a seamless browsing experience, allowing users to access and interact with web resources efficiently.
HTML Parsing
The rendering engine begins retrieving the contents of the requested document from the networking layer, typically in 8 kB chunks. The primary responsibility of the HTML parser is to transform the HTML markup into a structured representation known as a parse tree.
The output tree, referred to as the “parse tree,” consists of a hierarchy of DOM (Document Object Model) element and attribute nodes. The DOM serves as the object representation of the HTML document, providing an interface for HTML elements to interact with external scripts, such as JavaScript. The root of this tree is the “Document” object, and prior to any scripting manipulations, the DOM maintains an almost one-to-one correspondence with the original markup.
The Parsing Algorithm
HTML cannot be parsed effectively using traditional top-down or bottom-up parsers due to several factors:
- Forgiving Nature of the Language: HTML is designed to be lenient with syntax errors, allowing browsers to display content even when the markup is not perfectly structured.
- Browser Error Tolerance: Browsers are built to handle common cases of invalid HTML, ensuring that users have a functional experience.
- Reentrancy of the Parsing Process: In other programming languages, the source remains unchanged during parsing. However, in HTML, dynamic elements (like
<script>tags containingdocument.write()calls) can modify the input during parsing, which necessitates a different approach.
Because of these challenges, browsers employ a custom parser tailored for HTML. The parsing algorithm is thoroughly described in the HTML5 specification and consists of two primary stages: tokenization and tree construction.
Actions When Parsing is Finished
Once the parsing is complete, the browser proceeds to fetch external resources linked to the page, such as CSS stylesheets, images, and JavaScript files. At this point, the browser marks the document as interactive and begins parsing scripts that are in “deferred” mode, meaning those scripts are intended to execute after the document has been fully parsed. The document state is then set to “complete,” and a “load” event is triggered.
Importantly, browsers do not generate an “Invalid Syntax” error for HTML pages. Instead, they automatically correct any invalid content and continue processing the document, ensuring that users can view web pages with minimal disruption.
CSS Interpretation
The process of CSS interpretation involves several key steps:
- Parsing CSS Files: The browser parses external CSS files, the contents within
<style>tags, and the values withinstyleattributes. This parsing follows the “CSS lexical and syntax grammar,” which defines the rules and structure of valid CSS. - Creating StyleSheet Objects: Each parsed CSS file is transformed into a
StyleSheetobject. EachStyleSheetobject encapsulates the CSS rules, including selectors and the corresponding CSS declarations. This structured representation allows for efficient access and manipulation of styles. - Parsing Techniques: The CSS parser can utilize either top-down or bottom-up parsing techniques, depending on the specific parser generator employed. These techniques determine how the parser reads and processes the CSS rules, affecting the efficiency and accuracy of the parsing process.

Through this interpretation, the browser builds a comprehensive understanding of how to apply styles to the HTML elements in the DOM, facilitating the rendering of the web page with the intended visual presentation.
Page Rendering
The rendering process of a web page involves several structured steps:
- Creating the Frame Tree: The rendering engine constructs a ‘Frame Tree’ or ‘Render Tree’ by traversing the DOM nodes and calculating the computed CSS styles for each node. This tree represents the visual structure of the page.
- Calculating Preferred Width: The preferred width for each node in the Frame Tree is calculated in a bottom-up manner. This involves summing the preferred widths of the child nodes along with the node’s horizontal margins, borders, and padding.
- Calculating Actual Width: The actual width of each node is determined in a top-down approach by distributing the available width among its children based on their needs.
- Calculating Height: The height of each node is calculated bottom-up by applying text wrapping and summing the heights of the child nodes along with the node’s margins, borders, and padding.
- Determining Node Coordinates: The coordinates of each node are computed using the width and height information gathered in the previous steps.
- Handling Complex Elements: More intricate calculations are performed for elements that are floated, positioned absolutely or relatively, or that employ other complex features. For further details, refer to the CSS specifications at CSS2 and the current CSS work.
- Creating Layers: Layers are created to describe which parts of the page can be animated together without requiring re-rasterization. Each frame/render object is assigned to a specific layer.
- Allocating Textures: Textures are allocated for each layer of the page to optimize rendering performance.
- Executing Drawing Commands: The frame/render objects for each layer are traversed, and drawing commands are executed for their respective layers. This rendering can be handled by the CPU or directly drawn on the GPU using technologies like D2D (Direct2D) or SkiaGL.
- Reusing Calculated Values: The rendering process can leverage calculated values from the previous rendering of the webpage, enabling more efficient incremental changes that require less computational work.
- Compositing Layers: The final page layers are sent to the compositing process, where they are combined with other visible content, such as the browser chrome, iframes, and addon panels.
- Finalizing Render Commands: The final layer positions are computed, and composite commands are issued via graphics APIs like Direct3D or OpenGL. The GPU command buffers are flushed to the GPU for asynchronous rendering, and the completed frame is sent to the window server for display.

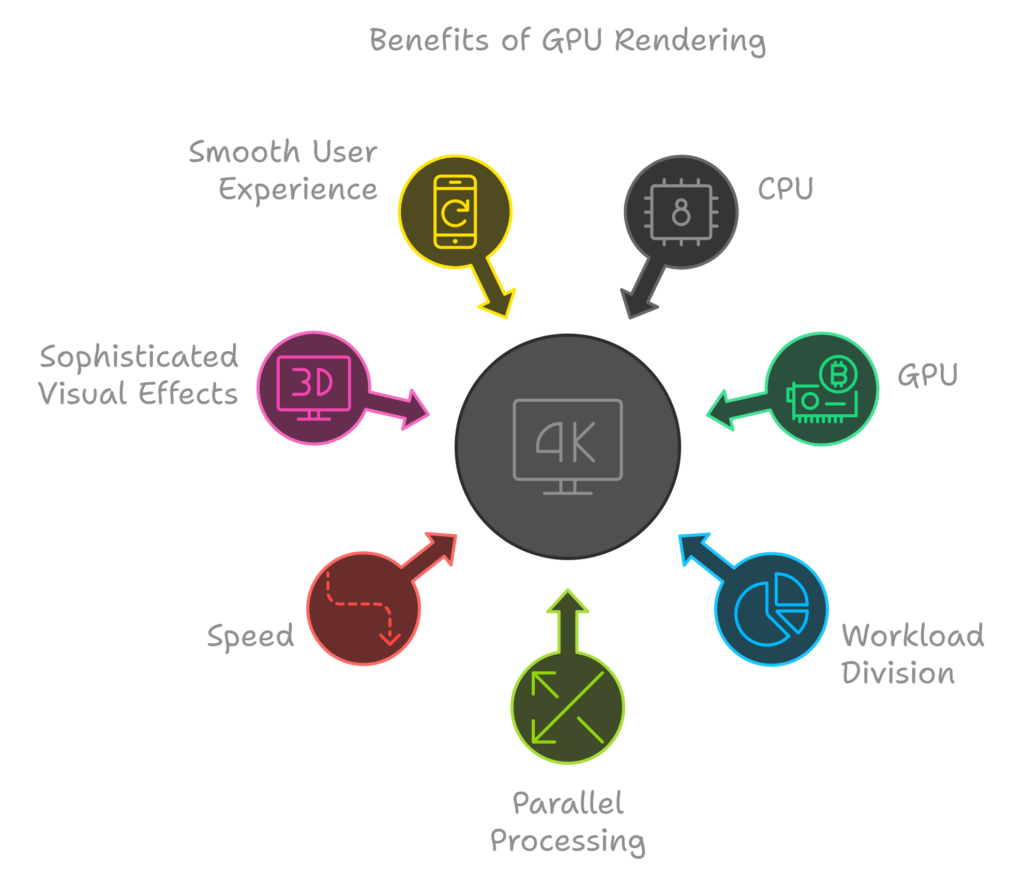
GPU Rendering
- During the rendering process, graphical computing tasks can utilize either the general-purpose CPU or the specialized graphical processor GPU.
- When leveraging the GPU for graphical rendering computations, the graphical software layers divide the workload into multiple smaller tasks. This approach allows them to take full advantage of the GPU’s massive parallelism, which is particularly effective for the floating-point calculations required in the rendering process.
- The GPU excels in handling numerous operations simultaneously, making it well-suited for rendering complex visual content efficiently and rapidly. This parallel processing capability significantly enhances performance, especially in applications involving high-resolution graphics, animations, and real-time rendering.
- As a result, using the GPU not only speeds up the rendering process but also enables more sophisticated visual effects and smoother user experiences in modern web applications and graphics-intensive software.
Post-Rendering and User-Induced Execution
After the rendering process is complete, the browser executes JavaScript code triggered by various events, such as timing mechanisms (like a Google Doodle animation) or user interactions (e.g., typing a query into the search box and receiving suggestions).
- Plugins: Additionally, plugins such as Flash or Java may also execute, although they typically do not run at this point on the Google homepage.
- Network Requests: JavaScript scripts can initiate further network requests, fetching additional resources or data as needed.
- DOM Modifications: These scripts have the ability to modify the existing page or its layout, which can lead to another round of page rendering and painting. This dynamic capability allows for interactive experiences, where content can change in real-time based on user actions or other conditions, enhancing the overall functionality and responsiveness of the web application.
- The interaction between JavaScript execution and the rendering engine is crucial for creating rich, engaging web experiences, allowing developers to build applications that respond intuitively to user input and changing contexts.
Introduction to Networks
The ability to deliver and exchange information over the world’s communication networks has revolutionized how people work, play, and live. At the turn of the century, the U.S. National Academy of Engineering produced a list of 20 technologies that made the most significant impact on society in the 20th century. This list included life-changing innovations such as electrification, the automobile, and the airplane. Among these were four key technological achievements in communication: radio and television, the telephone, the Internet, and computers—technologies whose underpinnings we will explore in this text.
Somewhat surprisingly, the Internet ranked only #13 on this list. The committee explained that this was because it was developed toward the latter part of the century and believed the most dramatic and significant impacts of the Internet would occur in the 21st century. Looking at the first decade of this century, that sentiment appears accurate. The ubiquitous spread of wireless networks and mobile devices, the advent of social networks, and the ability to communicate anytime and from anywhere are not only changing the face of commerce and our ability to stay in touch with friends but are also instrumental in massive societal and political changes.
Communication is fundamental to our modern existence. It is hard to imagine life without the Internet and its applications or without some form of networked mobile device. In early 2011, over 5 billion mobile phones were active worldwide, with over a billion having “broadband” network connectivity. To put this number in perspective, it is larger than the number of people in the world who, in 2011, had electricity, shoes, toothbrushes, or toilets!
Objectives
What makes our communication networks work? This text aims to explore the answers to this question. There are two main reasons why this topic is worth studying. First, it helps us understand the key design principles and basic analytical techniques used in communication systems. Second, the technical concepts involved also arise in various other fields of computer science (CS) and electrical engineering (EE), making the study of communication systems an excellent context for introducing widely applicable concepts.
Traditionally, in both education and research, “low-level communication” has been viewed primarily as an EE topic, focusing on how information moves across a single communication link. Similarly, “networking” has been considered a CS topic, primarily addressing how to construct communication networks from multiple links. Many traditional courses on digital communication seldom concern themselves with network construction and operation, while most courses on computer networks treat the intricacies of communication over physical links as a black box. Consequently, many individuals develop a deep understanding of either one topic or the other, but few become experts in every aspect of the problem. This division is one way to tackle the immense complexity of the subject.
Our goal in this text is to bridge the gap by understanding both the CS and EE aspects of digital communications. We also aim to demonstrate how various abstractions allow different parts of the system to be designed and modified without necessitating a close examination (or even a complete understanding) of what occurs in other parts of the system.
One drawback of maintaining strict boundaries between different components of a communication system is that the inner workings of other components may remain a mystery, even to practicing engineers. In the context of communication systems, this mystery often presents itself in phrases like “above my layer” or “below my layer.” While we will appreciate the benefits of these abstraction boundaries, an important goal of this text is to explore the critical principles and ideas essential for the complete design of a communication system. We strive to convey both the breadth and depth of the field.
We cover communication systems from the very beginning, starting with the source, which has information to transmit. We will explore how messages are broken into packets for network transmission, how these packets are converted into bits—each a “0” or a “1”—and how these bits are represented as signals, which are analog waveforms sent over physical communication links (such as wires, fiber-optic cables, radio, or acoustic waves).
Additionally, we study a range of communication networks, from the simplest dedicated point-to-point links to shared media comprising a set of communicating nodes sharing a common physical communication medium, and finally to larger multi-hop networks that connect to other networks, forming even larger systems.
Themes
At the core of all digital communication systems and networks lie three fundamental challenges: reliability, sharing, and scalability. Understanding these challenges is essential for the design and operation of effective communication systems.
-
Reliability:
- Reliability ensures that data is transmitted accurately and without loss. In any communication system, errors can occur due to noise, interference, or packet loss. Protocols and techniques such as error detection and correction, retransmission mechanisms, and robust signal processing are employed to enhance reliability. Ensuring that messages reach their destination intact is crucial for maintaining trust and efficiency in communication.
-
Sharing:
- Sharing refers to the efficient allocation of communication resources among multiple users or devices. In networks where multiple entities are competing for limited bandwidth, strategies must be implemented to ensure fair and efficient access. This can involve techniques such as multiplexing, scheduling algorithms, and access control protocols that determine how resources are allocated to minimize congestion and maximize throughput.
-
Scalability:
- Scalability addresses the ability of a communication system to accommodate a growing number of users or an increasing amount of data without compromising performance. As the demand for data communication rises, systems must be designed to expand efficiently. This involves both architectural considerations—such as hierarchical network structures and distributed systems—and technological advancements that enable faster processing and greater capacity.
These challenges are interconnected; for instance, improving reliability may require additional resources, impacting sharing and scalability. Effective communication system design seeks to balance these challenges to create robust, efficient, and scalable solutions that meet the demands of users in an ever-evolving digital landscape.
Learn More about Networking: https://ocw.mit.edu/courses/6-02-introduction-to-eecs-ii-digital-communication-systems-fall-2012/pages/readings/
Browser Networking
Performance is a feature. This text provides a hands-on overview of what every web developer needs to know about the various types of networks (WiFi, 3G/4G), transport protocols (UDP, TCP, and TLS), application protocols (HTTP/1.1, HTTP/2), and APIs available in the browser (XHR, WebSocket, WebRTC, and more) to deliver the best—fast, reliable, and resilient—user experience.
Primer on Latency and Bandwidth
Speed Is a Feature
The emergence and rapid growth of the web performance optimization (WPO) industry in recent years highlight the increasing importance and demand for speed in user experiences. This is not merely a psychological preference for speed in our fast-paced, interconnected world; it is a necessity driven by empirical results that significantly impact the bottom-line performance of online businesses.
Key Findings on Speed:
- Faster sites lead to better user engagement.
- Faster sites lead to better user retention.
- Faster sites lead to higher conversions.
In essence, speed is a feature that must be prioritized in web development and design. To deliver an optimal user experience, it is essential to understand the various factors and fundamental limitations affecting network performance. This chapter will focus on two critical components that dictate the performance of all network traffic: latency and bandwidth.
Latency
- Definition: Latency is defined as the time it takes for a packet of data to travel from the source to the destination.
- Impact: High latency can result in noticeable delays, affecting user interactions and overall satisfaction. Reducing latency is crucial for achieving a responsive user experience.
Bandwidth
- Definition: Bandwidth refers to the maximum throughput of a logical or physical communication path.
- Impact: Higher bandwidth allows more data to be transmitted simultaneously, leading to faster loading times and improved performance. However, it is essential to balance bandwidth with latency to optimize the overall user experience.

Armed with a better understanding of how bandwidth and latency work together, we will then have the tools to dive deeper into the internals and performance characteristics of TCP, UDP, and all application protocols above them.
Decreasing Transatlantic Latency with Hibernia Express
Latency is an important criteria for many high-frequency trading algorithms in the financial markets, where a small edge of a few milliseconds can translate to millions in loss or profit.
In September 2015, Hibernia Networks launched a new fiber-optic link (“Hibernia Express”) specifically designed to ensure the lowest latency between New York and London by following the great circle route between the cities. The total cost of the project is estimated to be $300M+ and the new route boasts 58.95 ms latency between the cities, which gives it a ~5 millisecond edge compared to all other existing transatlantic links. This translates to $60M+ per millisecond saved!
Latency is expensive — literally and figuratively.
The Many Components of Latency
Latency is the time it takes for a message, or a packet, to travel from its point of origin to its destination. While this definition is straightforward, it often conceals a wealth of information. Each system comprises multiple sources, or components, that contribute to the overall time it takes for a message to be delivered. Understanding these components and the factors influencing their performance is crucial.
Let’s delve into some common components contributing to latency, particularly in the context of a typical router on the Internet, which relays messages between the client and the server:
- Propagation Delay
- Definition: This is the time required for a message to travel from the sender to the receiver.
- Influencing Factors: Propagation delay is a function of distance and the speed at which the signal propagates through the medium. Typically, the propagation speed is close to the speed of light, with only minor variations depending on the medium used (e.g., fiber optics, copper cables).
- Transmission Delay
- Definition: This is the time required to push all bits of the packet into the link.
- Influencing Factors: Transmission delay depends on the packet’s length and the data rate of the link. For instance, transmitting a file over a slower link will take longer than over a faster one, regardless of distance.
- Processing Delay
- Definition: This is the time required to process the packet header, check for bit-level errors, and determine the packet’s destination.
- Influencing Factors: Processing delay varies based on the efficiency of the router’s hardware and software. More complex routing algorithms or heavy loads can increase processing time.
- Queuing Delay
- Definition: This is the time a packet spends waiting in a queue until it can be processed.
- Influencing Factors: Queuing delay is affected by network congestion and the number of packets waiting to be processed. A heavily congested network can lead to significant delays.
Total Latency Calculation
The total latency between the client and the server is the sum of all these delays:
[ \text{Total Latency} = \text{Propagation Delay} + \text{Transmission Delay} + \text{Processing Delay} + \text{Queuing Delay} ]
Example
To illustrate the impact of transmission delay, consider the transmission of a 10 MB file over two different links: one with a speed of 1 Mbps and another with a speed of 100 Mbps.
- 1 Mbps Link:
- Transmission Delay = ( \frac{10 \text{ MB} \times 8 \text{ bits/MB}}{1 \text{ Mbps}} = 80 \text{ seconds} )
- 100 Mbps Link:
- Transmission Delay = ( \frac{10 \text{ MB} \times 8 \text{ bits/MB}}{100 \text{ Mbps}} = 0.8 \text{ seconds} )
This example illustrates how transmission speed can drastically affect overall latency, highlighting the importance of optimizing both the hardware and software in communication networks for better performance.
Note
Network data rates are typically measured in bits per second (bps), whereas data rates for non-network equipment are typically shown in bytes per second (Bps). This is a common source of confusion, pay close attention to the units.
For example, to put a 10 megabyte (MB) file “on the wire” over a 1Mbps link, we will need 80 seconds. 10MB is equal to 80Mb because there are 8 bits for every byte!
Once a packet arrives at the router, several processes occur that contribute to additional latency:
- Packet Examination
- Description: The router examines the packet header to determine the appropriate outgoing route. This process may also involve various checks on the data for integrity and correctness.
- Impact on Latency: Although much of this logic is now handled by hardware, resulting in minimal delays, the time taken for examination still contributes to overall latency. The efficiency of the router’s hardware can significantly affect this delay.
- Queuing Delay
- Description: If packets arrive at a rate faster than the router can process them, they are queued in an incoming buffer.
- Impact on Latency: The time data spends waiting in the buffer is referred to as queuing delay. This delay can vary depending on network congestion and the router’s capacity to handle incoming packets.
Cumulative Delays
Each packet traveling over the network incurs multiple instances of the aforementioned delays, contributing to the total latency experienced during transmission:
- Propagation Delay: The farther the distance between the source and destination, the longer it takes for the signal to propagate.
- Processing Delay: With more intermediate routers along the route, each additional router adds its own processing delay to the packet’s journey.
- Transmission Delay: The larger the packet size and the slower the data rate of the links, the longer the transmission delay.
- Queuing Delay: Higher traffic loads increase the likelihood of packets being queued, resulting in longer delays.
Overall Impact on Network Performance
The cumulative effect of these delays can significantly impact network performance, especially in scenarios involving high traffic volumes or long distances. Understanding these factors is essential for optimizing network designs and improving overall communication efficiency. Addressing these delays through better hardware, load balancing, and network management strategies can lead to enhanced performance and user experience.
Bufferbloat in Your Local Router
Bufferbloat is a term that was coined and popularized by Jim Gettys in 2010, and is a great example of queuing delay affecting the overall performance of the network.
The underlying problem is that many routers are now shipping with large incoming buffers under the assumption that dropping packets should be avoided at all costs. However, this breaks TCP’s congestion avoidance mechanisms (which we will cover in the next chapter), and introduces high and variable latency delays into the network.
The good news is that the new CoDel active queue management algorithm has been proposed to address this problem, and is now implemented within the Linux 3.5+ kernels. To learn more, refer to “Controlling Queue Delay” in ACM Queue.
Speed of Light and Propagation Latency
As outlined by Einstein in his theory of special relativity, the speed of light represents the maximum speed at which all energy, matter, and information can travel. This observation imposes a hard limit on the propagation time of any network packet.
The good news is that the speed of light is extraordinarily high: approximately 299,792,458 meters per second (or 186,282 miles per second). However, this is the speed of light in a vacuum. In practice, packets travel through various media, such as copper wires or fiber-optic cables, which slow down the signal (see Table below). The ratio of the speed of light in a vacuum to the speed at which light travels through a material is known as the refractive index. A higher refractive index indicates that light travels more slowly in that medium.
For instance, the typical refractive index of optical fiber, through which most of our packets travel for long-distance hops, ranges from approximately 1.4 to 1.6. Although improvements in material quality are gradually reducing the refractive index, a simple rule of thumb is to assume that the speed of light in fiber is around 200,000,000 meters per second, which corresponds to a refractive index of approximately 1.5. The remarkable aspect of this is that we are already operating within a small constant factor of the maximum speed—a significant engineering achievement in its own right.
| Route | Distance | Time, light in vacuum | Time, light in fiber | Round-trip time (RTT) in fiber |
|---|---|---|---|---|
| New York to San Francisco | 4,148 km | 14 ms | 21 ms | 42 ms |
| New York to London | 5,585 km | 19 ms | 28 ms | 56 ms |
| New York to Sydney | 15,993 km | 53 ms | 80 ms | 160 ms |
| Equatorial circumference | 40,075 km | 133.7 ms | 200 ms | 200 ms |
The speed of light is indeed fast, but it still takes approximately 160 milliseconds for a round trip (RTT) from New York to Sydney. The figures presented in Table may appear overly optimistic, as they assume the packet travels over a fiber-optic cable along the great-circle path (the shortest distance between two points on the globe) between the two cities. In practice, however, this is rarely the case. The packet typically takes a much longer route between New York and Sydney, with each hop along the way introducing additional routing, processing, queuing, and transmission delays. Consequently, the actual RTT between New York and Sydney over existing networks typically falls within the 200–300 millisecond range. All things considered, that still seems relatively fast, right?
We may not commonly measure our everyday interactions in milliseconds, but studies have shown that most individuals reliably perceive “lag” once a delay of over 100–200 milliseconds is introduced into the system. Once the delay exceeds the 300-millisecond threshold, interactions are often described as “sluggish.” When the delay reaches the 1,000-millisecond (1 second) barrier, many users have already performed a mental context switch while waiting for a response — see “Speed, Performance, and Human Perception.”
The point is straightforward: to deliver the best user experience and keep users engaged with the task at hand, our applications need to respond within hundreds of milliseconds. This requirement leaves little room for error, particularly concerning the network. To succeed, managing network latency must be a carefully considered and explicit design criterion at all stages of development.
Note
Content delivery network (CDN) services provide many benefits, but chief among them is the simple observation that distributing the content around the globe, and serving that content from a nearby location to the client, enables us to significantly reduce the propagation time of all the data packets.
We may not be able to make the packets travel faster, but we can reduce the distance by strategically positioning our servers closer to the users! Leveraging a CDN to serve your data can offer significant performance benefits.
Last-Mile Latency
Ironically, it is often the last few miles—rather than the crossing of oceans or continents—that introduce significant latency: the infamous last-mile problem. To connect your home or office to the Internet, your local Internet Service Provider (ISP) must route cables throughout the neighborhood, aggregate the signal, and forward it to a local routing node. In practice, depending on the type of connectivity, routing methodology, and deployed technology, these initial hops can introduce latency of tens of milliseconds.
According to the annual “Measuring Broadband America” reports conducted by the Federal Communications Commission (FCC), last-mile latencies for terrestrial-based broadband (DSL, cable, fiber) within the United States have remained relatively stable over time. Fiber generally offers the best average performance (10-20 ms), followed by cable (15-40 ms), and DSL (30-65 ms).
In practical terms, this translates to 10-65 ms of latency just to reach the closest measuring node within the ISP’s core network, before the packet is even routed to its final destination! While the FCC report focuses on the United States, last-mile latency remains a challenge for all Internet providers, regardless of geography. For those curious, a simple traceroute can provide valuable insights into the topology and performance of your Internet provider.
$ traceroute google.com
traceroute to google.com (74.125.224.102), 64 hops max, 52 byte packets
1 10.1.10.1 (10.1.10.1) 7.120 ms 8.925 ms 1.199 ms
2 96.157.100.1 (96.157.100.1) 20.894 ms 32.138 ms 28.928 ms
3 x.santaclara.xxxx.com (68.85.191.29) 9.953 ms 11.359 ms 9.686 ms
4 x.oakland.xxx.com (68.86.143.98) 24.013 ms 21.423 ms 19.594 ms
5 68.86.91.205 (68.86.91.205) 16.578 ms 71.938 ms 36.496 ms
6 x.sanjose.ca.xxx.com (68.86.85.78) 17.135 ms 17.978 ms 22.870 ms
7 x.529bryant.xxx.com (68.86.87.142) 25.568 ms 22.865 ms 23.392 ms
8 66.208.228.226 (66.208.228.226) 40.582 ms 16.058 ms 15.629 ms
9 72.14.232.136 (72.14.232.136) 20.149 ms 20.210 ms 18.020 ms
10 64.233.174.109 (64.233.174.109) 63.946 ms 18.995 ms 18.150 ms
11 x.1e100.net (74.125.224.102) 18.467 ms 17.839 ms 17.958 ms - 1st hop: Local wireless router
- 11th hop: Google server
In this example, the packet started in Sunnyvale, bounced to Santa Clara, then Oakland, returned to San Jose, and was routed to the “529 Bryant” data center, ultimately arriving at its destination on the 11th hop. This entire process took, on average, 18 milliseconds—not bad, considering the packet could have traversed most of the continental USA in that time!
Last-mile latencies can vary significantly between ISPs due to differences in deployed technology, network topology, and even the time of day. As an end user, if you are looking to improve your web browsing speeds, it’s essential to measure and compare the last-mile latencies of the various providers available in your area.
Note:
Latency, not bandwidth, is the performance bottleneck for most websites! To understand why, we need to understand the mechanics of TCP and HTTP protocols — subjects we’ll be covering in subsequent chapters.
Measuring Latency with Traceroute
Traceroute is a simple network diagnostics tool for identifying the routing path of the packet and the latency of each network hop in an IP network. To identify the individual hops, it sends a sequence of packets toward the destination with an increasing “hop limit” (1, 2, 3, and so on). When the hop limit is reached, the intermediary returns an ICMP Time Exceeded message, allowing the tool to measure the latency for each network hop.
On Unix platforms the tool can be run from the command line via traceroute, and on Windows it is known as tracert.
Bandwidth in Core Networks
An optical fiber acts as a simple “light pipe,” slightly thicker than a human hair, designed to transmit light between its two ends. While metal wires are also used for data transmission, they suffer from higher signal loss, electromagnetic interference, and increased lifetime maintenance costs. In practice, your packets will likely travel over both types of cables, but for any long-distance hops, they will be transmitted over fiber-optic links.
Optical fibers have a distinct advantage when it comes to bandwidth, as each fiber can carry multiple wavelengths (channels) of light through a process known as wavelength-division multiplexing (WDM). Consequently, the total bandwidth of a fiber link is the product of the per-channel data rate and the number of multiplexed channels.
As of early 2010, researchers had achieved the ability to multiplex over 400 wavelengths, with a peak capacity of 171 Gbit/s per channel. This translates to over 70 Tbit/s of total bandwidth for a single fiber link! To match this throughput, we would require thousands of copper wire (electrical) links.
Not surprisingly, most long-distance hops—such as subsea data transmission between continents—are now conducted over fiber-optic links. Each cable typically contains several strands of fiber, with four strands being a common configuration. This arrangement can result in bandwidth capacities in the hundreds of terabits per second for each cable.
Bandwidth at the Network Edge
The backbones, or fiber links, that form the core data paths of the Internet are capable of moving hundreds of terabits per second. However, the available capacity at the edges of the network is significantly lower and varies widely based on the deployed technology. This includes options such as dial-up, DSL, cable, various wireless technologies, fiber-to-the-home, and even the performance of the local router. The available bandwidth to the user is determined by the lowest capacity link between the client and the destination server.
Akamai Technologies operates a global Content Delivery Network (CDN), with servers positioned around the globe. They provide free quarterly reports on average broadband speeds, as measured by their servers. Table below captures the macro trends as of late 2015.
| Rank | Country | Average Mbps | Year-over-year change |
|---|---|---|---|
| – | Global | 5.1 | 14% |
| 1 | South Korea | 20.5 | -19% |
| 2 | Sweden | 17.4 | 23% |
| 3 | Norway | 16.4 | 44% |
| 4 | Switzerland | 16.2 | 12% |
| 5 | Hong Kong | 15.8 | -2.7% |
| … | |||
| 21 | United States | 12.6 | 9.4% |
The preceding data excludes traffic from mobile carriers, a topic we will revisit later for a closer examination. For now, it’s essential to note that mobile speeds are highly variable and generally slower. Even with this context, the average global broadband bandwidth in late 2015 was only 5.1 Mbps. South Korea led the world with an impressive average throughput of 20.5 Mbps, while the United States ranked 21st with a speed of 12.6 Mbps.
To provide a frame of reference, streaming an HD video can require anywhere from 2 to 10 Mbps, depending on the resolution and codec used. Thus, while an average user in the United States can stream high-resolution video at the network edge, doing so would consume much of their available link capacity — not an ideal scenario for a household with multiple users.
Identifying the bandwidth bottleneck for any given user can be a nontrivial yet critical exercise. For those curious, several online services, such as Speedtest.net operated by Ookla, offer upstream and downstream tests against nearby servers. Choosing a local server for testing is important, and we will explore this further in our discussion on TCP. Running a test on one of these services is an effective way to verify whether your connection meets the advertised speeds of your local ISP.
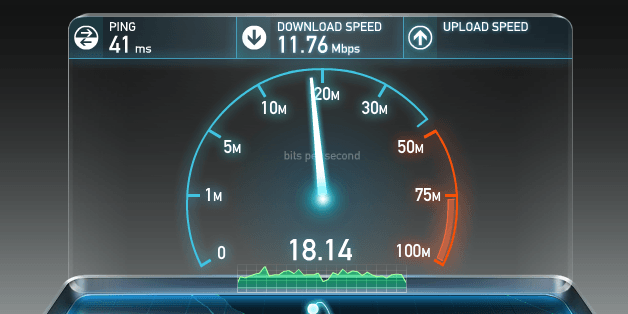
However, while a high-bandwidth link to your ISP is desirable, it is also not a guarantee of end-to-end performance; just because a bandwidth test promises high data rates does not mean that you can or should expect same performance from other remote servers. The network could be congested at any intermediate node due to high demand, hardware failures, a concentrated network attack, or a host of other reasons. High variability of throughput and latency performance is an inherent property of our data networks — predicting, managing, and adapting to the continuously changing “network weather” is a complex task.
Delivering Higher Bandwidth and Lower Latencies
Our demand for higher bandwidth is growing rapidly, largely driven by the surge in streaming video, which now accounts for well over half of all internet traffic. The encouraging news is that while increasing bandwidth may not be inexpensive, there are multiple strategies available to expand capacity. We can add more fibers into our fiber-optic links, deploy additional links across congested routes, or enhance Wavelength Division Multiplexing (WDM) techniques to transmit more data through existing infrastructure.
TeleGeography, a telecommunications market research and consulting firm, estimated that as of 2011, we were using, on average, only 20% of the available capacity of deployed subsea fiber links. More importantly, between 2007 and 2011, over half of the added capacity in trans-Pacific cables was attributed to WDM upgrades. In essence, the same fiber links were enhanced with better technology at both ends, allowing more data to be multiplexed. Naturally, there are limits to these advances, as every medium eventually hits a point of diminishing returns. However, as long as economic conditions allow, there is no fundamental reason why bandwidth throughput cannot continue to grow. In the worst case, additional fiber links can always be deployed.
Challenges in Improving Latency
Improving latency, however, is a much more complex challenge. Enhancing the quality of fiber links—using materials with lower refractive indices or deploying faster routers—could bring us marginally closer to the speed of light. But since our current transmission speeds already reach about two-thirds of that limit, these optimizations would only yield a modest 30% improvement at best. Unfortunately, the immutable laws of physics dictate that the speed of light imposes a hard boundary on minimum achievable latency.
If we can’t make light travel faster, we could instead shorten the distance it travels. The shortest path between two points on the globe is the great-circle route. Yet, laying new cables along these optimal paths isn’t always feasible due to physical, social, political, and financial constraints.
Therefore, to improve application performance, we need to design and optimize protocols and networking code with a clear understanding of bandwidth constraints and the speed of light’s limits. This involves reducing round trips, moving data closer to the client, and developing applications that mitigate latency through techniques like caching, pre-fetching, and more, as discussed in the subsequent sections of the course.
The Building Blocks of TCP
The Core Protocols: IP and TCP
At the heart of the Internet lie two fundamental protocols: IP (Internet Protocol) and TCP (Transmission Control Protocol). IP handles host-to-host routing and addressing, while TCP provides the abstraction of a reliable network atop an unreliable channel. Together, these form what is commonly known as the Internet Protocol Suite or TCP/IP, initially proposed by Vint Cerf and Bob Kahn in their 1974 paper titled “A Protocol for Packet Network Intercommunication.”
The original proposal, documented as RFC 675, underwent multiple revisions, culminating in the 1981 publication of the v4 specification of TCP/IP, which was divided into two distinct RFCs:
- RFC 791 — Internet Protocol (IP)
- RFC 793 — Transmission Control Protocol (TCP)
Since then, while TCP has seen many enhancements, the core operations have remained largely the same. It quickly replaced earlier networking protocols and became the backbone for popular applications like the World Wide Web, email, and file transfers.
TCP’s Role in Reliable Communication
TCP offers a robust abstraction of reliable communication over unreliable channels, managing the complexities of network transmission for applications. It ensures data retransmission, in-order delivery, congestion control, data integrity, and more. When using a TCP stream, you are guaranteed that the bytes sent will match the bytes received, and they will be delivered in the correct order. This reliability makes TCP ideal for accurate data transmission but also introduces some challenges when optimizing for web performance, especially in the browser.
Although HTTP doesn’t mandate TCP as the sole transport protocol (it could technically run over User Datagram Protocol (UDP) or others), in practice, virtually all HTTP traffic uses TCP due to its reliability and convenience.
Understanding the inner workings of TCP is essential for web optimization, even though most developers won’t interact with TCP sockets directly. Design choices at the application layer directly impact how TCP and the underlying network perform.
Intertwined History of TCP and IP Protocols
Many of us are familiar with IPv4 and IPv6, but what happened to IPv{1, 2, 3, 5}? The “4” in IPv4 stands for version 4 of the TCP/IP protocol suite, first published in September 1981. Originally, TCP and IP were proposed as a unified protocol, but with the v4 draft, they were officially split into separate RFCs. Hence, the “4” in IPv4 refers to its version history with TCP—there were no standalone IPv1, IPv2, or IPv3 protocols.
In 1994, work began on Internet Protocol next generation (IPng), which later became IPv6. However, v5 was already assigned to the experimental Internet Stream Protocol (ST), a protocol that never gained significant traction. As a result, few people have heard of ST, and the next available version number became IPv6.
Three-Way Handshake
All TCP connections begin with a three-way handshake (Figure 2-1). Before the client and server can exchange any application data, they must first agree on starting packet sequence numbers, as well as other connection-specific variables. The sequence numbers are chosen randomly from both sides for security purposes.
- SYN
The client picks a random sequence numberxand sends a SYN (synchronize) packet, which may also include additional TCP flags and options. - SYN-ACK
The server incrementsxby one, chooses its own random sequence numbery, appends its own flags and options, and sends a SYN-ACK (synchronize-acknowledge) packet in response. - ACK
The client increments bothxandyby one, then completes the handshake by sending the final ACK packet.

Once this three-way handshake is complete, application data can begin to flow between the client and the server. The client can send a data packet immediately after the ACK, while the server must wait for the ACK before dispatching its data. This startup process is mandatory for every TCP connection and carries an important implication for the performance of all network applications using TCP: every new connection incurs a full roundtrip of latency before any data transfer can begin.
For instance, if a client in New York establishes a new TCP connection with a server in London, the three-way handshake will take at least 56 milliseconds (Table 1-1). This is due to the 28 milliseconds it takes for the packet to propagate in one direction, followed by the return trip. Notably, the bandwidth of the connection does not affect this delay—it is purely governed by the propagation time between New York and London.
This delay, introduced by the three-way handshake, makes creating new TCP connections an expensive operation in terms of performance. This is one of the key reasons why connection reuse is an essential optimization for applications running over TCP.
TCP Fast Open
Loading a webpage often requires fetching hundreds of resources from dozens of different hosts, potentially creating many new TCP connections. Each connection must endure the overhead of the three-way handshake, which can be a major source of latency, especially on slower mobile networks.
To mitigate this issue, TCP Fast Open (TFO) was developed. TFO allows data transfer to begin within the SYN packet itself, eliminating the latency penalty of a full handshake. However, TFO comes with its own limitations:
- The maximum size of the data payload within the SYN packet is restricted.
- Only certain types of HTTP requests can be sent via TFO.
- TFO only works for repeat connections, as it requires a cryptographic cookie to be exchanged beforehand.
For more details on the capabilities and limitations of TFO, the latest IETF draft of “TCP Fast Open” is recommended.
Enabling TFO requires explicit support from the client, the server, and opt-in from the application. To optimize its usage, you should:
- Use Linux kernel version 4.1+ on the server.
- Use a compatible client (e.g., Linux, iOS 9+, or macOS 10.11+).
- Enable the necessary socket flags within the application.
Research conducted by Google, based on traffic analysis and network emulation, shows that TFO can reduce HTTP transaction network latency by 15%, decrease whole-page load times by over 10% on average, and by as much as 40% in high-latency scenarios.
Congestion Avoidance and Control
In the early 1980s, John Nagle introduced the term “congestion collapse,” which described a critical issue affecting networks with asymmetric bandwidth capacity between nodes. This phenomenon arose when the Transmission Control Protocol (TCP) and Internet Protocol (IP) were used together, leading to congestion problems particularly when gateways connected networks of different bandwidths.
Congestion collapse occurs when the round-trip time (RTT) exceeds the maximum retransmission interval for any host, causing that host to repeatedly send multiple copies of the same datagrams. Eventually, this overwhelms the network, filling the buffers in switching nodes, leading to packet drops. Even in this degraded state, the network remains stable as long as the packet drop selection algorithm is fair.
Nagle’s observations indicated that while ARPANET, the precursor to the modern Internet, had sufficient uniform bandwidth to avoid such issues, this would not last. As the number of nodes increased significantly, so did congestion incidents, drastically reducing network capacity and usability.
To manage these challenges, multiple mechanisms were introduced in TCP:
- Flow Control: This prevents the sender from overwhelming the receiver. Each side of the TCP connection advertises its receive window (rwnd), which indicates the buffer size available for incoming data. If a sender fails to keep pace with the receiver, it can signal a smaller window to prevent data overflow.
- Window Scaling (RFC 1323): Initially, TCP allocated 16 bits for the receive window, limiting the maximum size to 65,535 bytes. To address this, RFC 1323 introduced a scaling option to increase the window size up to 1 GB, communicated during the three-way handshake. This helps optimize performance, especially in high-bandwidth-delay networks.
- Slow-Start: This algorithm addresses the absence of a mechanism to prevent network overload. At the start of a new connection, TCP utilizes a congestion window (cwnd) initialized to a conservative value. As packets are acknowledged, the cwnd grows exponentially, allowing TCP to quickly discover the available bandwidth without overwhelming the network.
The Slow-Start Process
When a client connects to a server, the slow-start process helps assess the available bandwidth by gradually increasing the amount of data sent. Initially, the cwnd is set to a small value (usually a few segments). After sending packets, the server waits for acknowledgments (ACKs) before sending more data. For every ACK received, the cwnd increases, typically doubling the data sent until it reaches a threshold where congestion avoidance takes over.
This approach is crucial in maintaining optimal performance, particularly for web applications that run over TCP, as slow-start impacts the time it takes to reach desired throughput levels.
Slow-Start Restart (SSR)
TCP also incorporates slow-start restart (SSR), which resets the congestion window after a connection has been idle for a defined period. This mechanism allows TCP to adapt to potentially changed network conditions, but it can negatively impact long-lived connections. Disabling SSR is often recommended for better performance in these cases.
Example of Slow-Start Impact
In a scenario where a client in New York requests a 64 KB file from a server in London with a roundtrip time of 56 ms:
- New TCP Connection:
- Total time: 264 ms to transfer the file.
- Performance impacted by the slow-start phase and three-way handshake.
- Existing TCP Connection:
- Total time: 96 ms.
- Significant improvement due to the absence of the slow-start phase.
Increasing TCP’s Initial Congestion Window
Adjusting the initial cwnd size to the value specified in RFC 6928 (10 segments) can substantially enhance performance across various applications. Most modern operating systems have adopted this increase, contributing to improved efficiency for TCP connections.
Congestion Avoidance Mechanism
Once TCP has established a connection and has entered the congestion avoidance phase, it uses packet loss as feedback to adjust its performance. Slow-start initializes a conservative window, which grows until packet loss occurs, indicating potential network congestion. Upon loss, TCP adjusts its window to avoid further packet drops, adopting a sawtooth pattern in throughput trace due to this dynamic adjustment.
Research and development in TCP congestion control are ongoing, with various adaptations emerging to cater to different network types and data transfer requirements.
In summary, understanding and managing TCP congestion control mechanisms, such as flow control, slow-start, and congestion avoidance, are vital for optimizing network performance, particularly as traffic continues to grow in complexity and volume.
Bandwidth-Delay Product
The built-in congestion control and congestion avoidance mechanisms in TCP carry another important performance implication: the optimal sender and receiver window sizes must vary based on the roundtrip time and the target data rate between them.
To understand why this is the case, first recall that the maximum amount of unacknowledged, in-flight data between the sender and receiver is defined as the minimum of the receive (rwnd) and congestion (cwnd) window sizes: the current receive windows are communicated in every ACK, and the congestion window is dynamically adjusted by the sender based on the congestion control and avoidance algorithms.
If either the sender or receiver exceeds the maximum amount of unacknowledged data, then it must stop and wait for the other end to ACK some of the packets before proceeding. How long would it have to wait? That’s dictated by the roundtrip time between the two!Bandwidth-delay product (BDP)
Product of data link’s capacity and its end-to-end delay. The result is the maximum amount of unacknowledged data that can be in flight at any point in time.
If either the sender or receiver are frequently forced to stop and wait for ACKs for previous packets, then this would create gaps in the data flow, which would consequently limit the maximum throughput of the connection. To address this problem, the window sizes should be made just big enough, such that either side can continue sending data until an ACK arrives back from the client for an earlier packet — no gaps, maximum throughput. Consequently, the optimal window size depends on the roundtrip time! Pick a low window size, and you will limit your connection throughput, regardless of the available or advertised bandwidth between the peers.

So how big do the flow control (rwnd) and congestion control (cwnd) window values need to be? The actual calculation is a simple one. First, let us assume that the minimum of the cwnd and rwnd window sizes is 16 KB, and the roundtrip time is 100 ms:

Regardless of the available bandwidth between the sender and receiver, this TCP connection will not exceed a 1.31 Mbps data rate! To achieve higher throughput we need to raise the window size or lower the roundtrip time.
Similarly, we can compute the optimal window size if we know the roundtrip time and the available bandwidth on both ends. In this scenario, let’s assume that the roundtrip time stays the same (100 ms), but the sender has 10 Mbps of available bandwidth, and the receiver is on a high-throughput 100 Mbps+ link. Assuming there is no network congestion between them, our goal is to saturate the 10 Mbps link available to the client:

The window size needs to be at least 122.1 KB to saturate the 10 Mbps link. Recall that the maximum receive window size in TCP is 64 KB unless window scaling — see Window Scaling (RFC 1323) — is present: double-check your client and server settings!
The good news is that the window size negotiation and tuning is managed automatically by the network stack and should adjust accordingly. The bad news is sometimes it will still be the limiting factor on TCP performance. If you have ever wondered why your connection is transmitting at a fraction of the available bandwidth, even when you know that both the client and the server are capable of higher rates, then it is likely due to a small window size: a saturated peer advertising low receive window, bad network weather and high packet loss resetting the congestion window, or explicit traffic shaping that could have been applied to limit throughput of your connection.
Bandwidth-Delay Product in High-Speed LANs
BDP is a function of the roundtrip time and the target data rate. Hence, while the roundtrip time is a common bottleneck in cases with high propagation delay, it can also be a bottleneck on a local LAN!
To achieve 1 Gbit/s with 1 ms roundtrip time, we would also need a congestion window of at least 122 KB. The calculation is exactly the same as we saw earlier; we simply added a few zeroes to the target data rate and removed the same amount of zeroes from the roundtrip latency.
Head-of-Line Blocking
TCP provides the abstraction of a reliable network running over an unreliable channel, which includes basic packet error checking and correction, in-order delivery, retransmission of lost packets, as well as flow control, congestion control, and congestion avoidance designed to operate the network at the point of greatest efficiency. Combined, these features make TCP the preferred transport for most applications.
However, while TCP is a popular choice, it is not the only, nor necessarily the best choice for every occasion. Specifically, some of the features, such as in-order and reliable packet delivery, are not always necessary and can introduce unnecessary delays and negative performance implications.
To understand why that is the case, recall that every TCP packet carries a unique sequence number when put on the wire, and the data must be passed to the receiver in-order. If one of the packets is lost en route to the receiver, then all subsequent packets must be held in the receiver’s TCP buffer until the lost packet is retransmitted and arrives at the receiver. Because this work is done within the TCP layer, our application has no visibility into the TCP retransmissions or the queued packet buffers, and must wait for the full sequence before it is able to access the data. Instead, it simply sees a delivery delay when it tries to read the data from the socket. This effect is known as TCP head-of-line (HOL) blocking.
The delay imposed by head-of-line blocking allows our applications to avoid having to deal with packet reordering and reassembly, which makes our application code much simpler. However, this is done at the cost of introducing unpredictable latency variation in the packet arrival times, commonly referred to as jitter, which can negatively impact the performance of the application.

Further, some applications may not even need either reliable delivery or in-order delivery: if every packet is a standalone message, then in-order delivery is strictly unnecessary, and if every message overrides all previous messages, then the requirement for reliable delivery can be removed entirely. Unfortunately, TCP does not provide such configuration — all packets are sequenced and delivered in order.
Applications that can deal with out-of-order delivery or packet loss and that are latency or jitter sensitive are likely better served with an alternate transport, such as UDP.
Packet Loss Is OK
In fact, packet loss is necessary to get the best performance from TCP! A dropped packet acts as a feedback mechanism, which allows the receiver and sender to adjust their sending rates to avoid overwhelming the network, and to minimize latency; see Bufferbloat in Your Local Router. Further, some applications can tolerate packet loss without adverse effects: audio, video, and game state updates are common examples of application data that do not require either reliable or in-order delivery — incidentally, this is also why WebRTC uses UDP as its base transport.
If a packet is lost, then the audio codec can simply insert a minor break in the audio and continue processing the incoming packets. If the gap is small, the user may not even notice, and waiting for the lost packet runs the risk of introducing variable pauses in audio output, which would result in a much worse experience for the user.
Similarly, if we are delivering game state updates, then waiting for a packet describing its state at time T-1, when we already have the packet for time T is often simply unnecessary — ideally, we would receive each and every update, but to avoid gameplay delays, we can accept intermittent loss in favor of lower latency.
Optimizing for TCP
TCP is an adaptive protocol designed to be fair to all network peers and to make the most efficient use of the underlying network. Thus, the best way to optimize TCP is to tune how TCP senses the current network conditions and adapts its behavior based on the type and the requirements of the layers below and above it: wireless networks may need different congestion algorithms, and some applications may need custom quality of service (QoS) semantics to deliver the best experience.
The close interplay of the varying application requirements, and the many knobs in every TCP algorithm, make TCP tuning and optimization an inexhaustible area of academic and commercial research. In this chapter, we have only scratched the surface of the many factors that govern TCP performance. Additional mechanisms, such as selective acknowledgments (SACK), delayed acknowledgments, and fast retransmit, among many others, make each TCP session much more complicated (or interesting, depending on your perspective) to understand, analyze, and tune.
Having said that, while the specific details of each algorithm and feedback mechanism will continue to evolve, the core principles and their implications remain unchanged:
- TCP three-way handshake introduces a full roundtrip of latency.
- TCP slow-start is applied to every new connection.
- TCP flow and congestion control regulate throughput of all connections.
- TCP throughput is regulated by current congestion window size.
As a result, the rate with which a TCP connection can transfer data in modern high-speed networks is often limited by the roundtrip time between the receiver and sender. Further, while bandwidth continues to increase, latency is bounded by the speed of light and is already within a small constant factor of its maximum value. In most cases, latency, not bandwidth, is the bottleneck for TCP.
Tuning Server Configuration
As a starting point, prior to tuning any specific values for each buffer and timeout variable in TCP, of which there are dozens, you are much better off simply upgrading your hosts to their latest system versions. TCP best practices and underlying algorithms that govern its performance continue to evolve, and most of these changes are available only in the latest kernels. In short, keep your servers up to date to ensure the optimal interaction between the sender’s and receiver’s TCP stacks.
Note: On the surface, upgrading server kernel versions seems like trivial advice. However, in practice, it is often met with significant resistance: many existing servers are tuned for specific kernel versions, and system administrators are reluctant to perform the upgrade. To be fair, every upgrade brings its risks, but to get the best TCP performance, it is also likely the single best investment you can make.
With the latest kernel in place, it is good practice to ensure that your server is configured to use the following best practices.
A larger starting congestion window allows TCP to transfer more data in the first roundtrip and significantly accelerates the window growth.
Disabling slow-start after idle will improve performance of long-lived TCP connections that transfer data in periodic bursts.
Enabling window scaling increases the maximum receive window size and allows high-latency connections to achieve better throughput.
Allows application data to be sent in the initial SYN packet in certain situations. TFO is a new optimization, which requires support both on client and server; investigate if your application can make use of it.
The combination of the preceding settings and the latest kernel will enable the best performance — lower latency and higher throughput — for individual TCP connections.
Depending on your application, you may also need to tune other TCP settings on the server to optimize for high connection rates, memory consumption, or similar criteria. Consult your platform documentation and read through “TCP Tuning for HTTP” document maintained by the HTTP Working Group for additional advice.
Note: For Linux users, ss is a useful power tool to inspect various statistics for open sockets. From the command line, run ss --options --extended --memory --processes --info to see the current peers and their respective connection settings.
Tuning Application Behavior
Tuning performance of TCP allows the server and client to deliver the best throughput and latency for an individual connection. However, how an application uses each new, or established, TCP connection can have an even greater impact:
- No bit is faster than one that is not sent; send fewer bits.
- We can’t make the bits travel faster, but we can move the bits closer.
- TCP connection reuse is critical to improve performance.
Eliminating unnecessary data transfers is, of course, the single best optimization — e.g., eliminating unnecessary resources or ensuring that the minimum number of bits is transferred by applying the appropriate compression algorithm. Following that, locating the bits closer to the client, by geo-distributing servers around the world — e.g., using a CDN — will help reduce latency of network roundtrips and significantly improve TCP performance. Finally, where possible, existing TCP connections should be reused to minimize overhead imposed by slow-start and other congestion mechanisms.
Performance Checklist
Optimizing TCP performance pays high dividends, regardless of the type of application, for every new connection to your servers. A short list to put on the agenda:
- Investigate “TCP Tuning for HTTP” recommendations.
- Upgrade server kernel to latest version.
- Ensure that cwnd size is set to 10.
- Ensure that window scaling is enabled.
- Disable slow-start after idle.
- Investigate enabling TCP Fast Open.
- Eliminate redundant data transfers.
- Compress transferred data.
- Position servers closer to the user to reduce roundtrip times.
- Reuse TCP connections whenever possible.
That is all we need to know for now. If want to learn about system-networks other than browsers, SS7 and other things, click here.
IP Addressing
The internet continues to grow at a phenomenal rate. This is reflected in the tremendous popularity of the World Wide Web (WWW), the numerous opportunities businesses find in reaching customers through virtual storefronts, and the emergence of innovative business models.
It is clear that expanding business operations and increasing public awareness will further amplify the demand for access to internet resources.
Internet Scaling Problems
Over the past few years, the Internet has encountered two major scaling issues as it strives to support continuous and uninterrupted growth:
- The eventual exhaustion of IPv4 (Internet Protocol version 4) address space
- The increasing need to route traffic between the ever-growing number of networks that make up the Internet
The first issue relates to the depletion of the IPv4 address space. IPv4 uses a 32-bit address system, which means there are only 2³² (4,294,967,296) unique IPv4 addresses available. As the Internet continues to expand, this limited pool of addresses will eventually be exhausted.
The address shortage problem is further compounded by two key factors:
- Inefficient allocation of portions of the IP address space
- The limitations of traditional classful addressing, which prevents optimal utilization of the available address pool.
The Address Lifetime Expectancy (ALE) Working Group of the Internet Engineering Task Force (IETF) has raised concerns that if current address allocation policies remain unchanged, the Internet may face near- to medium-term exhaustion of its remaining unallocated IP addresses. Without a resolution to this issue, new users may be unable to connect to the global Internet.
Currently, more than half of all possible IPv4 addresses have already been assigned to Internet Service Providers (ISPs), corporations, and government agencies. However, it is estimated that only 69 million addresses are actively in use, highlighting the inefficient distribution of the address space.
The second problem arises from the rapid growth in the size of Internet routing tables. Internet backbone routers must maintain complete routing information for the entire Internet. Over the years, routing tables have seen exponential growth as an increasing number of organizations connect to the Internet.
To illustrate this growth:
- In December 1990, there were 2,190 routes.
- By December 1995, the number had surged to over 30,000 routes.
- By December 2000, the total exceeded 100,000 routes.
This significant increase in routing information presents challenges for efficient data traffic management and network performance.
Unfortunately, the routing problem cannot be resolved merely by installing more router memory or increasing the size of routing tables. Other factors contributing to the capacity problem include:
- The growing demand for CPU horsepower to compute routing table and topology changes.
- The increasingly dynamic nature of WWW connections and their impact on router forwarding caches.
- The sheer volume of information that must be managed by both people and machines.
If the number of entries in the global routing table continues to increase without bounds, core routers will be compelled to drop routes, resulting in portions of the Internet becoming unreachable.
The long-term solution to these issues lies in the widespread deployment of IP Next Generation (IPng or IPv6). Currently, IPv6 is undergoing testing and implementation on the 6Bone network, an informal collaborative project that spans North America, Europe, and Japan. The 6Bone supports the routing of IPv6 packets, as this functionality has not yet been integrated into many production routers.
Until IPv6 can be deployed globally, IPv4 patches will need to be utilized and modified to maintain the universal connectivity that users have come to expect.
Classful IP Addressing
When IP was first standardized in September 1981, the specification mandated that each system connected to an IP-based Internet be assigned a unique 32-bit Internet address.
Systems with interfaces to more than one network require a unique IP address for each network interface. The structure of an Internet address consists of two parts:
- The first part identifies the network on which the host resides.
- The second part identifies the specific host on that network.
This creates a two-level addressing hierarchy.
In recent years, the network number field has come to be known as the network prefix. This is because the leading portion of each IP address identifies the network number.
Key points regarding network prefixes:
- All hosts on a given network share the same network prefix but must have a unique host number.
- Conversely, any two hosts on different networks must have different network prefixes but may share the same host number.
Primary Address Classes
To provide the necessary flexibility for supporting networks of varying sizes, the designers of the Internet established a division of the IP address space into three address classes: Class A, Class B, and Class C. This approach is commonly referred to as classful addressing.
Each class sets the boundary between the network prefix and the host number at a different point within the 32-bit address, allowing for a more tailored allocation of IP addresses based on the specific needs of different networks.
One of the fundamental features of classful IP addressing is the inclusion of a self-encoding key within each address, which indicates the dividing point between the network prefix and the host number. For instance, if the first two bits of an IP address are 10, the dividing point is located between the 15th and 16th bits.
This mechanism simplified the routing system during the early years of the Internet, as the original routing protocols did not provide a deciphering key or mask with each route to specify the length of the network prefix.
Class A Networks (/8 Prefixes)
Each Class A network address features an 8-bit network prefix, with the highest order bit set to 0 and a 7-bit network number, followed by a 24-bit host number. Today, Class A networks are commonly referred to as “/8s” (pronounced “slash eight” or simply “eights”) due to their 8-bit network prefix.
A maximum of 126 (/8 networks) can be defined. This calculation subtracts two because:
- The /8 network 0.0.0.0 is reserved for use as the default route.
- The /8 network 127.0.0.0 (also written as 127/8 or 127.0.0.0/8) is reserved for the loopback function.
Each /8 network supports a maximum of 16,777,214 hosts (calculated as 2^{24} – 2). The subtraction of two accounts for:
- The all-0s host number (representing “this network”).
- The all-1s host number (representing “broadcast”).
Since the /8 address block contains 2,147,483,648 individual addresses (2^{31}) and the IPv4 address space contains a maximum of 4,294,967,296 addresses (2^{32}), the /8 address space constitutes 50 percent of the total IPv4 unicast address space.
Class B Networks (/16 Prefixes)
Each Class B network address features a 16-bit network prefix, with the two highest order bits set to 1-0. It includes a 14-bit network number, followed by a 16-bit host number. Class B networks are commonly referred to as “/16s” due to their 16-bit network prefix.
A maximum of 16,384 (/16 networks) can be defined, each supporting up to 65,534 hosts (calculated as 2^{16} – 2). The subtraction of two accounts for:
- The all-0s host number (representing “this network”).
- The all-1s host number (representing “broadcast”).
Since the entire /16 address block contains 1,073,741,824 addresses (2^{30}), it represents 25 percent of the total IPv4 unicast address space.
Class C Networks (/24 Prefixes)
Each Class C network address features a 24-bit network prefix, with the three highest order bits set to 1-1-0. It includes a 21-bit network number, followed by an 8-bit host number. Class C networks are commonly referred to as “/24s” due to their 24-bit network prefix.
A maximum of 2,097,152 (/24 networks) can be defined, each supporting up to 254 hosts (calculated as 28−22^8 – 228−2). The subtraction of two accounts for:
- The all-0s host number (representing “this network”).
- The all-1s host number (representing “broadcast”).
Since the entire /24 address block contains 536,870,912 addresses (2292^{29}229), it represents 12.5 percent (or one-eighth) of the total IPv4 unicast address space.
Other Classes
In addition to the three most popular classes (Class A, B, and C), there are two additional classes:
- Class D Addresses:
- Leading four bits set to 1-1-1-0.
- Used to support IP Multicasting.
- Class E Addresses:
- Leading four bits set to 1-1-1-1.
- Reserved for experimental use.
Dotted-Decimal Notation
To make Internet addresses easier for people to read and write, IP addresses are often expressed as four decimal numbers, each separated by a dot. This format is known as “dotted-decimal notation.”
Dotted-decimal notation divides the 32-bit Internet address into four 8-bit fields, specifying the value of each field independently as a decimal number. The fields are separated by dots.
Unforeseen Limitations to Classful Addressing
The original designers of the Internet did not anticipate the immense growth it would experience. Several key issues can be traced back to early decisions made during the Internet’s formative years:
-
Early Over-Allocation of IP Addresses:
During the initial stages, the seemingly unlimited address space led to IP addresses being allocated based on organizational requests rather than actual needs. As a result, addresses were freely assigned without concerns for the eventual depletion of the IP address space. -
The 32-Bit Address Limitation:
The decision to standardize on a 32-bit address space limited IPv4 to 4,294,967,296 addresses (2^32). Had the address space been slightly larger, it would have exponentially increased the number of available addresses, potentially preventing the current shortage. -
Inefficient Allocation with Classful Addressing:
The classful system (Classes A, B, and C) provided simple and easy-to-understand boundaries, but it did not promote efficient allocation of the finite IP address space. In particular, it failed to accommodate the needs of medium-sized organizations.- A /24 (supporting 254 hosts) was often too small, while a /16 (supporting 65,534 hosts) was too large.
- As a result, organizations with a few hundred hosts were frequently assigned an entire /16 block, even when two /24 blocks would have sufficed. This practice led to a premature depletion of /16 address space.
- Currently, only /24 addresses are readily available for medium-sized organizations, which can contribute to the rapid growth of the global Internet’s routing table.
Within the text itself while working with actual code, we will learn the concepts of Subnetting, VSLM, CIDR, and how to take advantage of IPv6, and HTTP/2 as a web developer.
HTML 5
Our HTML tutorial provides both basic and advanced concepts of HTML, tailored for beginners as well as professionals. Each topic is presented step-by-step, ensuring easy comprehension and learning. Whether you are new to HTML or aiming to enhance your skills to a professional level, our tutorial guides you through the essentials of HTML.
By mastering HTML, you will be equipped to create your own interactive and dynamic websites. While this tutorial focuses solely on HTML, mastering HTML in conjunction with CSS and JavaScript will enable you to build sophisticated web applications.
Start your journey into the world of web development with our comprehensive HTML tutorial today!
Major Points of HTML
- Definition: HTML stands for HyperText Markup Language.
- Purpose: HTML is used to create web pages and web applications.
- Popularity: HTML is a widely used language on the web.
- Static Websites: We can create a static website using HTML alone.
- Type: Technically, HTML is a markup language rather than a programming language.
In this tutorial, you will get a lot of HTML examples, at least one example for each topic with explanation. You may edit, use and commercially-use the examples within the text as long as you credit the web-page using a link or any other criterion.
What is HTML?
Introduction to HTML
HTML is an acronym that stands for HyperText Markup Language, which is used for creating web pages and web applications. Let’s break down the meaning of HyperText Markup Language and Web Page.
HyperText
HyperText simply means “text within text.” It refers to a text that contains links leading to other web pages. Whenever you click on a link that brings you to a new webpage, you engage with hypertext. This allows for connecting multiple web pages (HTML documents) together.
Markup Language
A markup language is a computer language used to apply layout and formatting conventions to a text document. It enhances text to become more interactive and dynamic, allowing it to transform into images, tables, links, and more.
Web Page
A web page is a document commonly written in HTML that is translated by a web browser. You can identify a web page by entering a URL. Web pages can be static or dynamic, and HTML is sufficient to create static web pages.
In summary, HTML is a markup language used to create attractive web pages with styling, ensuring they are displayed nicely in a web browser. An HTML document consists of various HTML tags, each containing different content.
Simple HTML Example
<!DOCTYPE html>
<html>
<head>
<title>Web Page Title</title>
</head>
<body>
<h1>Write Your First Heading</h1>
<p>Write Your First Paragraph.</p>
</body>
</html>Description of HTML Example
<!DOCTYPE>: Defines the document type and instructs the browser about the version of HTML.<html>: This tag informs the browser that the document is an HTML document. It acts as a container for all other elements, except for<!DOCTYPE>.<head>: The first element inside the<html>element, containing metadata (information about the document). It must be closed before the<body>tag opens.<title>: Used to add the title of the HTML page, which appears at the top of the browser window. It should be placed inside the<head>tag and closed immediately (optional).<body>: Contains the main content of the HTML document visible to users.<h1>: Indicates the first-level heading of the webpage.<p>: Denotes a paragraph of text on the webpage.
Brief History of HTML
In the late 1980s, physicist Tim Berners-Lee, a contractor at CERN, proposed a system for researchers. In 1989, he wrote a memo suggesting an internet-based hypertext system. Tim Berners-Lee is known as the father of HTML. The first available description of HTML was a document called “HTML Tags,” proposed by Tim in late 1991. The latest version of HTML is HTML5, which will be covered later in this tutorial.
HTML Versions
Since HTML was invented, many versions have been released. Here’s a brief overview:
- HTML 1.0: The first version, released in 1991, was a barebones version of HTML.
- HTML 2.0: Released in 1995, this version became the standard for website design, supporting features like form-based file upload and form elements (text boxes, option buttons, etc.).
- HTML 3.2: Published by W3C in early 1997, it supported table creation and complex mathematical equations, becoming an official standard.
- HTML 4.01: Released in December 1999, it is a stable version that supports stylesheets (CSS) and multimedia scripting.
- HTML5: The newest version, with its first draft announced in January 2008, is still under development by W3C and WHATWG.
Features of HTML
- Simplicity: HTML is easy to understand and modify.
- Effective Presentations: It allows for an effective presentation due to many formatting tags.
- Flexibility: As a markup language, it offers flexibility in web page design along with text.
- Linking Capabilities: HTML enables the addition of links, enhancing user browsing experience.
- Platform Independence: It can be displayed on any platform (Windows, Linux, Macintosh, etc.).
- Multimedia Support: HTML allows for the inclusion of graphics, videos, and sounds, making web pages more interactive.
- Case Insensitivity: HTML is a case-insensitive language, meaning tags can be used in lower or upper case.
Note: It is recommended to write all tags in lower case for consistency and readability.
We use a specific file extension to save our HTML 5 files, specifically .html. Although not necessary, but, is the standard practice. Any text file readable by the browser with the <!DOCTYPE html> declaration may work, but is discouraged, as new and upcoming browsers like ARC don’t work properly without .html file extension
Along with file extension, we also, use the file names such as index.html for the home page, though not again necessary. We also follow such standard practices in CSS(will learn later), like naming it style.css or a name defining its purpose like globalcss.css or global_styles.css. In the upcoming sections of the text we will also learn, JavaScript, and its naming schemes, TypeScript, Node.js, jQuery, React, Next.js, and other frameworks in the frontend.
HTML text Editors
- An HTML file is a text file, so to create an HTML file we can use any text editors.
- Text editors are the programs which allow editing in a written text, hence to create a web page we need to write our code in some text editor.
- There are various types of text editors available which you can directly download, but for a beginner, the best text editor is Notepad (Windows) or TextEdit (Mac).
- After learning the basics, you can easily use other professional text editors which are, Notepad++, Sublime Text, Vim, Visual Studio Code etc.
- In our tutorial, we will use Notepad and sublime text editor. Following are some easy ways to create your first web page with Notepad, and sublime text.
HTML code with Notepad. (Recommended for Beginners)
Notepad is a simple text editor and suitable for beginners to learn HTML. It is available in all versions of Windows, from where you easily access it.
Step 1: Open Notepad (Windows)

Step 2: Write code in HTML

Step 3: Save the HTML file with .htm or .html extension.

Step 4: Open the HTML page in your web browser.
To run the HTML page, you need to open the file location, where you have saved the file and then either double-click on file or click on open with option


DSDSds jmav uwlp pwxr kdcd
With 2024 passing, we’re starting 2025 with some fresh CryptoAIRDROPS!
We’ve created a list right here ethereum2025 . top.
We are still employing defi market players with solid pay and relocation to Dubai.
Make sure to give as a holla if you’re interested in participating in upcoming Crypto Dubai fiesta on January 19th Gatherers event!
Enjoy. On top of that, there’s an news regarding new airdrops right here, Know your customer policy is not required!